In NLP (Traditional Lexical) Evaluators, the one concept that unites all of them is n-gram overlap. An “n-gram” is just a sequence of ‘n’ words.
- 1-gram (unigram): “the”
- 2-gram (bigram): “the cat”
- 3-gram (trigram): “the cat sat”
These evaluators work by comparing the n-grams in the candidate text (what your AI generated) against the n-grams in one or more reference texts (the “ground truth” or human-written answers).
They do not understand meaning (semantics). They only understand matching words.
Here’s a breakdown:
1. BLEU Score (Bilingual Evaluation Understudy)
- Main Goal: Designed for machine translation. It measures how precise the candidate text is.
- How it Works: It asks, “What percentage of the words (and word sequences) in the candidate text also appear in the reference text?“
- Key Idea: Precision + Brevity Penalty
- Precision: If your candidate is “the cat sat,” and the reference is “the cat sat on the mat,” your 1-gram precision is 3/3 (100%) and your 3-gram precision is 1/1 (100%).
- Brevity Penalty (BP): This is the crucial part. What if your candidate was just “the”? The precision is 1/1 (100%), but it’s a terrible translation! The BP heavily punishes a candidate text that is much shorter than the reference.
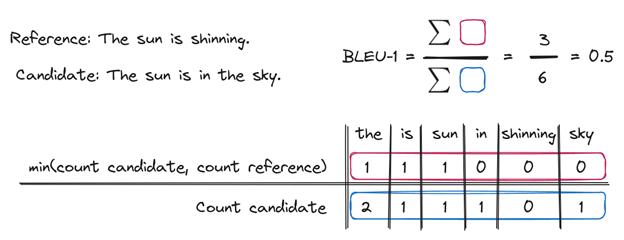
When to use it: Good for tasks where precision is key, like translation or text generation, to ensure the output is “faithful” to the reference.
2. ROUGE Score (Recall-Oriented Understudy for Gisting)
- Main Goal: Designed for automatic summarization. It’s the inverse of BLEU and measures recall.
- How it Works: It asks, “What percentage of the words (and word sequences) from the reference text were “recalled” or captured by the candidate text?“
- Key Idea: Recall-Based Variants
- ROUGE-N (e.g., ROUGE-1, ROUGE-2): This is just n-gram recall. ROUGE-1 (unigram recall) is the most common and checks if the candidate included the important individual words from the reference summary.
- ROUGE-L (Longest Common Subsequence): This is the most popular variant. It finds the longest chain of words that appear in both texts in the same order. This is great for summaries because it rewards keeping sentence structure intact, even if words are added or removed in between.
When to use it: This is the standard for summarization. It checks if your AI-generated summary included the main points from the human-written “ground truth” summary.
3. METEOR Score (Metric for Evaluation of Translation with Explicit ORdering)
- Main Goal: Designed as an improvement on BLEU for translation. It tries to be “smarter” and more flexible.
- How it Works: It does more than just exact n-gram matching.
- Alignment: It first aligns words between the candidate and reference.
- Flexible Matching: It matches synonyms (e.g., “fast” matches “quick”) and stems (e.g., “running” matches “run”). It uses WordNet (a lexical database) for this.
- Fragmentation Penalty: This is its secret sauce. It rewards matching words that are in contiguous chunks (in the right order) and penalizes them if the matches are “fragmented” or scattered all over the sentence.
When to use it: When you want a more robust score than BLEU that accounts for synonyms and word order, making it slightly more “semantic” (though still not truly understanding).
4. GLEU Score
This is a less common variant, often associated with Google’s translation work (and sometimes confused with the GLUE benchmark, which is a collection of tasks, not a single score). GLEU (Google-BLEU) calculates n-gram overlap but is designed to be a better correlate with human judgment. For most practical purposes, understanding BLEU and ROUGE will cover 95% of use cases for lexical evaluators.
Summary Table: Which One to Use?
| Metric | Main Use Case | Key Concept | Pros | Cons |
| BLEU | Translation | Precision + Brevity Penalty | Fast, popular, punishes “short” answers. | Doesn’t care about word order, synonyms, or if the meaning is right. |
| ROUGE | Summarization | Recall (especially ROUGE-L) | Great for checking if “main points” are covered. | Can be “gamed” by long, rambling summaries that include all the words. |
| METEOR | Translation (Improved) | Alignment + Synonyms + Fragmentation Penalty | “Smarter” than BLEU. Handles synonyms and word order. | Much slower to compute. Requires WordNet. |
Leave a Reply